Data Segregation is a concept to separate data view by using different filters and searches so that the data can be in much more understandable form then its normal form. In this regard, Webbee provides some awesome data filtration techniques to the user to filter the data as they want to be.
There are 3 ways that the user can filter the data as per their need.
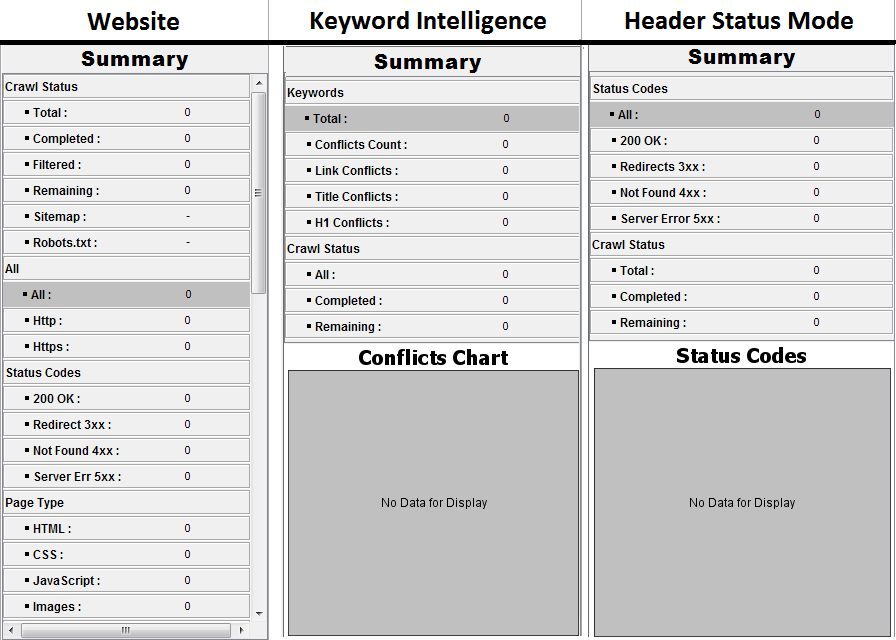
There is a panel in all three modes that display the crawl summary to the user and make them able to change the view as per that panel. See the image below.
The box highlighted is the filter. Right now and by-default “All” box is selected which display all the data that is being crawled by the spider. “200 OK” filter, after clicking, will display those webpages which have a 200 status code. Similarly other filter works other than “Crawl Status” area because that area just displays the status about crawl, not the data fetched by application.
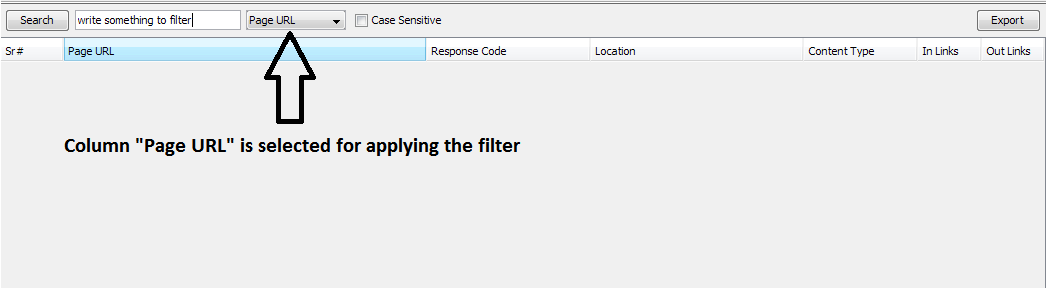
In all the tables a search box can be found at left side of panel. That box takes the text as input and applies it to the selected column and filters the data. See the below image.
1xbet: обзор слотов и казино игр для игроков из России
Россия – страна с богатой историей азартных игр. От древних времен люди с удовольствием рисковали своими средствами, надеясь на удачу. С появлением онлайн-казино и слотов, игроки получили возможность наслаждаться азартом прямо из своего дома. В этой статье мы рассмотрим одну из самых популярных платформ для игры – 1xbet. Мы расскажем о разнообразии слотов и казино игр, доступных для игроков из России, и поделимся с вами нашими мнениями и рекомендациями.
Сотни слотов и казино игр ждут вас на 1xbet. От классических фруктовых автоматов до современных видеослотов с захватывающими бонусными играми – здесь есть что-то для каждого игрока. Но какие из них стоит попробовать? Какие игры являются самыми популярными среди российских игроков? И какие слоты обещают наибольшие выигрыши? Присоединяйтесь к нам, чтобы узнать все о мире слотов и казино игр на 1xbet и выбрать свою удачную игру!
Основные особенности и преимущества слотов и казино игр на 1xbet для игроков из России
1xbet – это популярная онлайн-платформа, предлагающая широкий выбор слотов и казино игр для игроков из России. На сайте www.1xbetonline247.com вы найдете огромное количество увлекательных игр от ведущих разработчиков, таких как NetEnt, Microgaming, и Betsoft. Здесь вы сможете насладиться яркой и захватывающей графикой, интересными сюжетами и большими выигрышами. Благодаря удобному интерфейсу и интуитивно понятным настройкам, вы сможете легко найти свою любимую игру и начать играть прямо сейчас.
Кроме слотов, 1xbet также предлагает широкий выбор казино игр, таких как рулетка, блэкджек, покер и многое другое. Здесь вы найдете разнообразные варианты игр, от классических до современных, с разными ставками и правилами. Независимо от вашего уровня опыта, на сайте www.1xbetonline247.com вы найдете игру, которая подойдет именно вам. Присоединяйтесь к миллионам игроков и испытайте удачу уже сегодня!
Разнообразие игровых автоматов и казино игр на платформе 1xbet
1xbet – это популярный онлайн-букмекер, который предлагает не только ставки на спорт, но и широкий выбор слотов и казино игр для игроков из России. Независимо от ваших предпочтений, здесь вы обязательно найдете что-то по душе. В казино 1xbet представлены различные игры, включая классические слоты, рулетку, блэкджек, покер и многое другое.
Слоты в 1xbet – это настоящий рай для любителей азартных игр. Здесь вы найдете сотни популярных игровых автоматов от ведущих разработчиков, таких как NetEnt, Microgaming, Play’n GO и других. Большой выбор тематик и разнообразие игровых функций обеспечат увлекательное времяпрепровождение и шанс выиграть крупные призы. Кроме того, 1xbet регулярно проводит промоакции и турниры, где игроки могут получить дополнительные бонусы и возможность увеличить свои выигрыши.
1xbet предлагает высококачественное казино развлечение для игроков из России. Современный дизайн, удобный интерфейс и безопасная платформа делают игру комфортной и надежной. Благодаря поддержке различных платежных систем, вы можете легко пополнять свой счет и выводить выигрыши. Команда поддержки 1xbet всегда готова помочь вам в случае возникновения вопросов или проблем. Присоединяйтесь к 1xbet уже сегодня и наслаждайтесь захватывающими казино играми!
Безопасность и надежность игры на 1xbet: гарантии для игроков из России
1xbet – это популярная онлайн-платформа, предлагающая широкий выбор слотов и казино игр для игроков из России. Сайт предлагает увлекательный игровой опыт с возможностью выигрыша реальных денежных призов. В слотах 1xbet представлены разнообразные тематики, включая классические фруктовые автоматы, приключенческие слоты, игры с джекпотами и многое другое. Здесь каждый игрок сможет найти что-то по своему вкусу и насладиться захватывающими игровыми процессами.
Казино игры на 1xbet также предлагают множество вариантов для любителей азартных развлечений. В ассортименте доступны такие популярные игры, как покер, рулетка, блэкджек и многое другое. Каждая игра предлагает уникальную атмосферу и возможность испытать свою удачу. Кроме того, на 1xbet есть возможность играть в реальном времени с живыми дилерами, что добавляет дополнительного азарта и реалистичности в игровой процесс. Все игры представлены высококачественной графикой и звуковым сопровождением, чтобы игроки могли полностью погрузиться в мир азарта и развлечений.
Бонусы и промоакции для игроков слотов и казино игр на 1xbet
1xbet – это популярная онлайн-платформа, предлагающая широкий выбор слотов и казино игр для игроков из России. Сайт 1xbet является одним из ведущих игровых операторов, который предлагает своим пользователям множество развлечений и возможностей для выигрыша.
На сайте 1xbet вы найдете огромное количество слотов от ведущих разработчиков игр, таких как Microgaming, NetEnt, Playtech и других. Каждый слот имеет уникальную тематику, разнообразные бонусные функции и высокую отдачу. Независимо от того, предпочитаете ли вы классические слоты с фруктовыми символами или современные видео-слоты с захватывающими сюжетами, 1xbet предложит вам идеальный выбор.
Кроме слотов, на сайте 1xbet также представлены разнообразные казино игры. Здесь вы найдете все популярные классические игры, такие как рулетка, блэкджек, покер и многое другое. Каждая игра доступна в различных вариациях, с разными ставками и правилами, чтобы удовлетворить вкус каждого игрока. Благодаря высокому качеству графики и звукового сопровождения, вы будете погружены в атмосферу настоящего казино, не выходя из дома.
1xbet предлагает своим игрокам удобный интерфейс, быстрые выплаты и множество способов пополнения и вывода средств. Безопасность и конфиденциальность пользователей – приоритет для 1xbet, поэтому все транзакции осуществляются через защищенные каналы связи. Кроме того, игроки могут получить различные бонусы и приветственные предложения, которые помогут им увеличить свои шансы на выигрыш.
Оперативная поддержка и удобные условия для игроков из России на 1xbet
1xbet – это популярная онлайн-платформа, предлагающая широкий выбор слотов и казино игр для игроков из России. Сайт имеет простой и интуитивно понятный интерфейс, что делает его доступным даже для новичков. В 1xbet вы найдете множество различных слотов от ведущих разработчиков, таких как NetEnt, Microgaming, Play’n GO и других. Каждый слот имеет свою уникальную тематику и функции, что позволяет игрокам выбирать то, что больше всего им нравится.
Кроме слотов, 1xbet также предлагает широкий выбор казино игр. Здесь вы найдете все популярные игры, такие как рулетка, блэкджек, покер и многое другое. Казино игры доступны как в демо-режиме, так и на реальные деньги, что позволяет игрокам выбирать подходящий для них вариант. Кроме того, 1xbet предлагает различные бонусы и акции, которые позволяют игрокам увеличить свои выигрыши и получить еще больше удовольствия от игры.
В целом, 1xbet является отличным выбором для игроков из России, которые ищут разнообразие и качество в онлайн-казино. Благодаря широкому выбору слотов и казино игр, простому интерфейсу и различным бонусам, 1xbet предлагает все необходимое для увлекательного и прибыльного игрового опыта. Зарегистрируйтесь на 1xbet сегодня и начните наслаждаться игрой уже сейчас!
В заключение, 1xbet предлагает захватывающий мир азартных игр и слотов для игроков из России. Благодаря широкому выбору игр от ведущих разработчиков, каждый найдет что-то по своему вкусу. От классических слотов до захватывающих казино игр, 1xbet обеспечивает непревзойденное разнообразие и качество. Не только это, но также доступны различные бонусы и привлекательные акции, которые помогут увеличить ваши шансы на выигрыш. Не упустите возможность погрузиться в захватывающий мир азарта и развлечений с 1xbet!
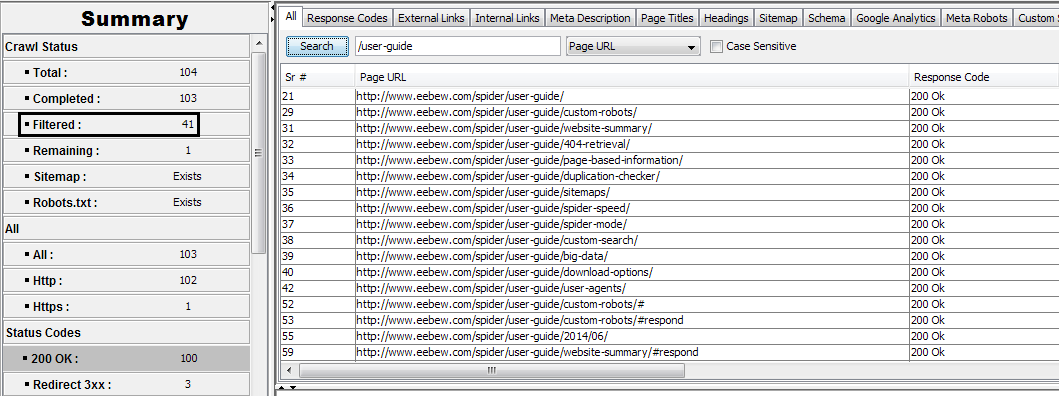
In above image first filter was applied by the panel i.e. 200 OK pages and then a search filter have also implemented by searching the “user-guide” in search box. This can be seen that outcome contain all the pages with 200 OK status code and they also contain “/user-guide” in them as search filter was implemented to “Page URL” column. This can also be observed in “Filtered:” field that filter count consisting on both the filters.
There can be instances when user requires URL filtration e.g. filter the URL on some parameter basis and do not crawl them. This requirement seems to be ‘never happened case’ but can be very helpful importantly when you have a website with user generated pages i.e. comments on blog, FAQs, search pages etc. Such pages can be a real harm if they are not catered (Disallowed in robots.txt and/or no-index) as they can create huge content duplication across the website and thin content pages as well. In such circumstances identifying those pages can be real tough.
These scenarios can be handled with Webbee’s Custom Robots Feature which is capable of filtering defined parameter’s URL from crawl and store them at separate place so that they can be identified. Parameters can be defined in Custom Robots just like we write a normal robots.txt e.g.

Asset Law Counsel preserved valuable family resources.
The tools are key for OBBBA compliance software success.